
Earlier this year I led a collaboration between Cray Supercomputers, Digital Catapult and Bloomsbury AI (my previous employer). This post is an informal report of how we used Cray’s compute resources to both boost the accuracy and accelerate the speed of training machine reading models. With parallel training, we were able to break accuracy records on the TriviaQA Wiki task, without any change in model architecture.
If you’re wondering how to scale up and parallelize your network training, there are excellent tools like Horovod that make it easy with almost no code changes required. Read on to find out how, and Enjoy!
Note: this post is edited from a blog post I wrote for Digital Catapult
Key Points:
- Bloomsbury AI’s product Cape answers natural language questions on free text documents (in english). Cape has diverse applications that range from customer service and regulatory compliance, to powering digital assistants.
- Working in partnership with Digital Catapult’s Machine Intelligence Garage, Cray provided Bloomsbury AI access to their Accel AI lab and a Cray CS-Storm, a powerful GPU cluster optimized for AI and Deep Learning.
- The goal was to improve the accuracy of the existing model architecture, to coincide with the open-sourcing of the Cape Project.
- Using the Cray CS-Storm and Horovod enabled a 10x speed up in training time, from over 200 hours on a GCP server to about 20 hours on the CS-Storm. Many parallel workers also lead to an increase in model accuracy, allowing Cape to become the state of the art in multi-document question answering on wikipedia documents at the time of publishing this post.
Bloomsbury AI and Cape
Cape, from Bloomsbury AI, is a complete end-to-end solution for an enterprise-scale question answering system, including models, back-end servers and front-end admin interfaces. Cape’s core functionality allows users to upload a free text documents to the system. A user can then pose questions (in natural language) to a document or collection of documents, and Cape will extract strings from the document(s) that best answer the inputted question. Cape can also be used as a python library for developers and hobbyists to integrate natural language question answering components into their systems. Cape can run in inference mode on a variety of different hardware, including locally and on cheap cpu-only servers on the cloud. Cape is designed to be strike an excellent balance between being accurate and scalable.
An example is shown in the image below. The document can be as short as a sentence or as long as several hundred paragraphs.

Figure 1: The above image shows a simple demo of the Cape. The document can be as short as a sentence or as long as several hundred paragraphs.
Cape is powered by a deep neural network that predicts the probability that a short span of text is the answer to an inputted question and document pair, a task known as machine comprehension, machine reading, or extractive question answering in the literature. Cape’s model is based on the document-qa model from Clark et al. 2017, augmented with an ELMo language model (Peters et al. 2018), and several other architectural tweaks. Cape is multipurpose, and is specifically trained in order to perform well on several diverse datasets simultaneously.
The inclusion of the ELMo language model is highly beneficial in terms of accuracy, especially on datasets such as SQUAD (Rajpurkar et al. 2016), but at the cost of significantly increasing the model’s training time, especially for longer documents.1
Cape uses an innovative caching strategy that allows it to answer quickly on documents it has seen before at inference time, but we were experiencing training times on typical cloud computing hardware of over 200 hours (an NVIDIA Tesla k80 GPU on a system with 40GB of CPU RAM). This training time severely limited the experiments that we could perform, whilst also incurring significant cost to business for server time.
Partnership with Digital Catapult, Cray AI Lab and CS-Storm
Cray, the world leading manufacturer of supercomputers, through it’s partnership with Digital Catapult is working with UK deep tech startups to help them access the compute resources they need to realise their business goals.
Through Machine Intelligence Garage, Digital Catapult’s programme to provide UK based machine learning startups with access to cutting edge compute resources, Cray’s Accel AI lab was able to provide Bloomsbury AI with access to a CS-Storm system, and the support of one of their in-house experts.
The Cray CS-Storm 500NX system is specifically built for AI workloads. The cluster used for this collaboration consists of 4 nodes, each with two 18 core Intel Xeon “Broadwell” CPUs with 512GB RAM and 8 NVIDIA Tesla V100 GPUs. The nodes are connected by InfiniBand connections, and the system is supported by a 55TB Cray ClusterStor Lustre filesystem.
The partnership’s goals were to demonstrate how Cray’s AI machines could be used to provide real business value, and showcasing the raw power of CS-Storm systems. The models that were to be trained on CS-Storm would be required to work with the rest of Cape’s technology. This provided the us with two constraints:
- The model architecture couldn’t significantly change
- The model’s size (parameters, number of layers etc) had to be constrained so that it could still run well on regular hardware (including CPUs).
As a result, we decided to focus on how the training regime could be modified to improve the model, and on accelerating the training process.
Note: we only had a short time to play with Cray’s machine, and couldn’t explore in the kind of detail I’d have liked - This is an informal, engineering piece, rather than a scientific one!
Experiments
Cape is trained on a several different datasets, some in-house, and others publicly available. One such dataset is the TriviaQA dataset from Joshi et al., 2017.
TriviaQA tests a Machine reading system’s ability to answer factual questions on full web and Wikipedia articles. The dataset itself is used in a distantly supervised paradigm. It consists of natural language questions, their answers, and a list of several Wikipedia or web articles that should contain the answers. These articles are split into chunks of a predefined number of words, and trained independently.2
Chunks that happen to contain the answer to the inputted question may not contain sufficient information to infer that the answer is indeed the correct answer. This is why the training regime for TriviaQA is said to be distantly supervised, as in practice, although most of these datapoints are correct, there is a fair amount of noise.
We shall focus on TriviaQA Wiki, the subset of TriviaQA concerned with answering questions on Wikipedia articles. This subset contains 77582 questions and 48822 Wikipedia articles, with an average of 1.79 articles per question.
There were two main avenues open for experimentation that would make good use of the CS-Storm whilst staying within the design constraints:
- More powerful hardware (in particular larger GPU memory) allows for the size of text chunks to be increased: This should improve performance by allowing the model to learn longer-distance dependencies, and reduce the amount of the noise in the dataset.
- Take advantage of multiple GPUs to train in a data-parallel paradigm: Using the amazing Horovod framework from Sergeev and Del Balso, 2018, We can distribute training on to many GPUs and nodes.3 The benefit of this is twofold. Firstly, it increases the training speed, and secondly, by increasing the effective mini-batch size, the average update is less noisy, which is especially important in our distant supervision training regime.
Results - Convergence speed
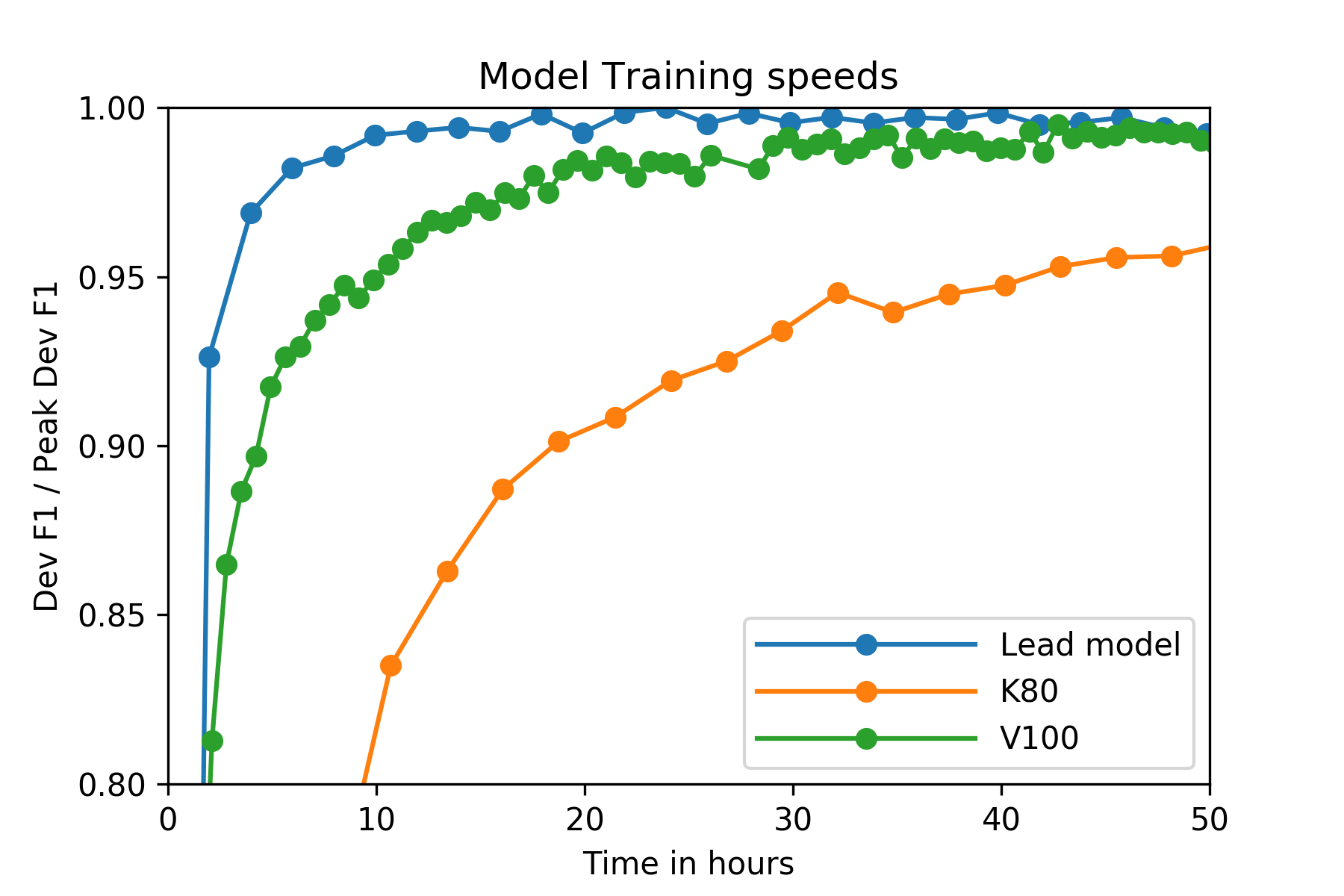
Figure 2: The graph above shows the learning curves for several different experimental setups, with the number of hours of training vs the accuracy relative to that model’s peak accuracy.
The figure shows the learning curves for several different experimental setups, with number of hours of training vs the accuracy relative that model’s peak accuracy.
The orange curve is for the control model, trained on short chunk lengths on a normal cloud server. The time taken to reach the optimal development accuracy was over 200 hours. The green curve shows an equivalent model trained using only one of the CS-Storm’s V100 GPUs. The time to peak performance is reduced to about 40 hours, a 5x speedup over the cloud server. The blue curve shows the final model’s learning curve, trained using 16 GPUs distributed across two of CS-Storm’s cores. This system not only breaks the state of the art for this dataset, it also takes less than 20 hours to train.
It is also worth noting that the final model achieved an accuracy within 5% of its peak accuracy in less than 4 hours of training, whereas this milestone took over 42 hours for the k80.
Results - Accuracy
Two metric used to assess model performance are Exact Match (EM) and F1 score. The EM score the percentage of extracted answers that exactly match the gold reference answer, and the F1 metric is the mean word overlap F1 between the extracted answer and gold reference answer.
Using two the CS-Storm nodes and 16 workers allowed for effective mini-batch sizes of 960, compared to 30 on the cloud server. Not only did this enable very fast training, it also compensated for the noise in the dataset considerably.
When using data parallelism, it is common practice to linearly scale the learning rate with the number of workers, (e.g. in Goyal et al. 2017). However, the focus of their research was a supervised learning task, with less noise in the training data. I found that linearly scaling the learning rate for our task led to instability and poor performance. However, not modifying the learning rate did not lead to accelerated training. A good compromise was to scale the learning rate by a factor of the square root of the number of workers, which empirically provided good performance and training speed. (Note that we only very briefly experimented with a learning rate warmup scheme, which should help with instability significantly.)
We also experimented with very long document chunk sizes. Because of the extreme length of these chunks, the training was considerably slower. This type of model looked very promising from an accuracy perspective. but had two major drawbacks - they took over 120 hours to train, even on the CS-Storm, and the performance degraded considerably when using these models in a production environment with shorter document chunk sizes.
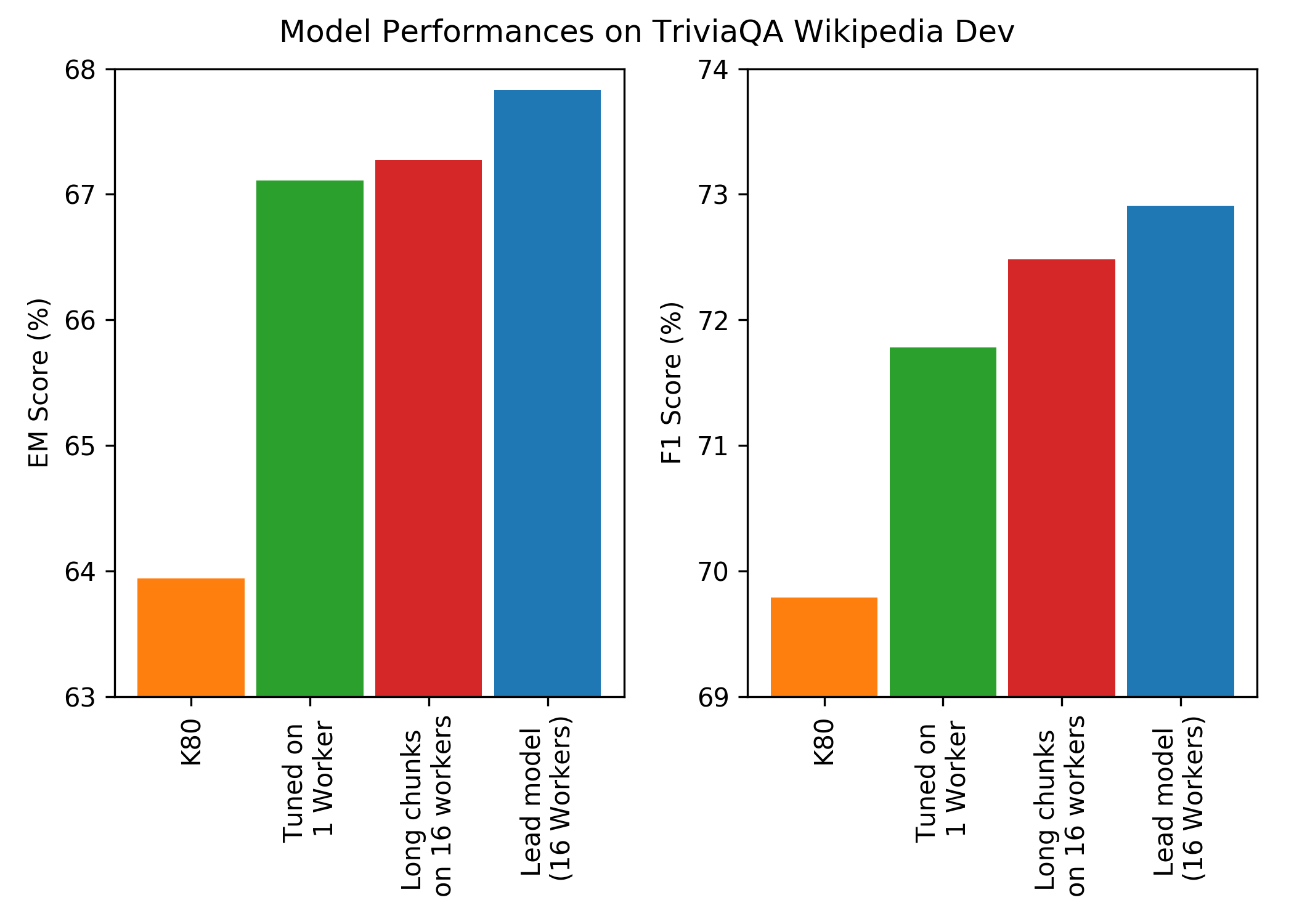
Figure 3: The graph shows the performance attained by different models on the development set of TriviaQA Wikipedia.
The figure shows the performance attained by different models on the development set of TriviaQA Wiki. It is apparent that hyperparameter tuning enabled by fast training has allowed significant performance improvement. Furthermore, training on longer document chunks looks promising, but requires further experimentation.4 The effect of large effective batch sizes can also be seen here, with increases of 0.72% EM and 1.12% F1 against an equivalent model trained on a single worker.
The best model was submitted to the official TriviaQA model leaderboard, which can be viewed here. The test set answers are withheld from the public release, allowing for fair testing of model performances. Our model received scores of 67.32% EM and 72.35% F1, setting a new state of the art. The test set also contains a verified subset, which has been curated by human annotators to be noise-free. On this subset the model scores 75.68% EM and 79.26% F1 indicating it answers an impressive ~80% of TriviaQA’s questions correctly.
Summing up
Since this project concluded, Bloomsbury AI has joined Facebook, and has released Cape Open-source to the community, including the best model from this project. We hope that it will be of benefit to many people, empowering them to create great, intelligent products.
To try Cape out, please check out the project here. Pull Requests for functionality, demos, tutorials and documentation are encouraged! In particular, we’d love to integrate BERT (Devlin et al. 2018) into Cape. I don’t have time for this at the moment but if you want to take on this project, please get in contact!
The team would like to thank Cray and Digital Catapult’s Machine Intelligence Garage for their support, expertise and hardware resources, without which, this work would not have been possible.
Citations
P. Goyal et al., “Accurate, Large Minibatch SGD: Training ImageNet in 1 Hour,” arXiv:1706.02677 [cs], Jun. 2017.
J. Devlin, M.-W. Chang, K. Lee, and K. Toutanova, “BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding,” arXiv:1810.04805 [cs], Oct. 2018.
M. E. Peters et al., “Deep contextualized word representations,” arXiv:1802.05365 [cs], Feb. 2018.
A. Sergeev and M. Del Balso, “Horovod: fast and easy distributed deep learning in TensorFlow,” arXiv:1802.05799 [cs, stat], Feb. 2018.
C. Clark and M. Gardner, “Simple and Effective Multi-Paragraph Reading Comprehension,” arXiv:1710.10723 [cs], Oct. 2017.
P. Rajpurkar, J. Zhang, K. Lopyrev, and P. Liang, “SQuAD: 100,000+ Questions for Machine Comprehension of Text,” arXiv:1606.05250 [cs], Jun. 2016.
M. Joshi, E. Choi, D. S. Weld, and L. Zettlemoyer, “TriviaQA: A Large Scale Distantly Supervised Challenge Dataset for Reading Comprehension,” arXiv:1705.03551 [cs], May 2017.
Footnotes
- This work was carried out during spring 2018, before the release of even more powerful contextual representations like BERT, (Devlin et al. 2018). We’d love to integrate BERT into Cape. I don’t have time for this at the moment but if you want to take on this project, please get in contact! ^
- for further details on training regime, see Clark et al. 2017 ^
- Each worker maintains a copy of the model being trained and computes parameter updates for a mini-batch. The parameter updates for all the workers are then averaged together using a highly efficient ring-allreduce method. All the workers’ models are then updated with the averaged parameter update. The overall effect is to increase the effective mini-batch size by a factor of the number of workers, i.e. 2 workers each computing updates with a mini-batch size of 64 training examples is equivalent to 1 worker with a mini-batch size of 128 training examples. Its a really lightweight solution that works on several frameworks, and requires only a couple of lines of code to be changed. Try it out! ^
- Training runs were terminated after 120 hours. Learning curves for the Long chunk models indicated that training had not yet converged after this time, suggesting the long context model could have ended up performing best. The drawbacks of this model have already been mentioned however, and it could not be put into production, so further experiments with it were stopped. ^