I maintain a repository to generated Question Answering training data using an unsupervised pipeline. With this project, you can train your own unsupervised question generators, or use ours to generate QA data in an unsupervised way on english paragraphs. The repository can be used to reproduce results in our paper “Unsupervised Question Answering by Cloze Translation”
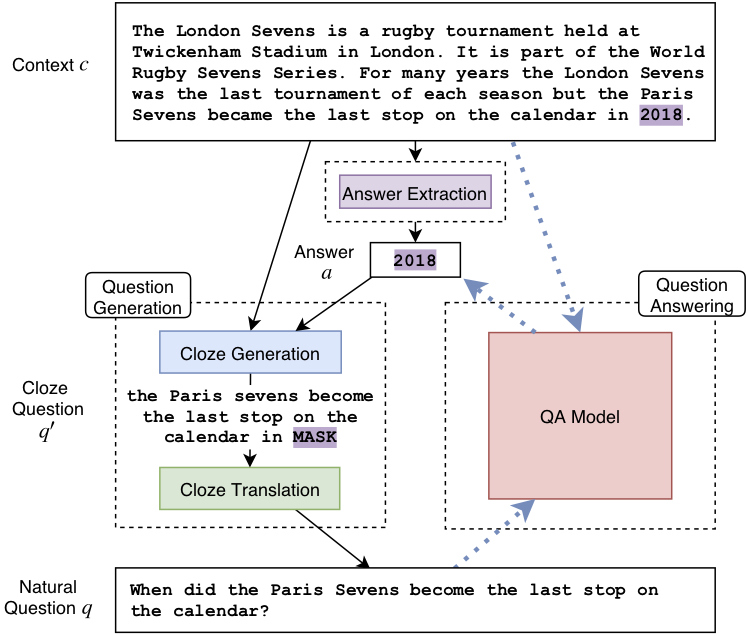
Obtaining training data for Question Answering (QA) is time-consuming and resource-intensive, and existing QA datasets are only available for limited domains and languages. In this work, we take some of the first steps towards unsupervised QA, and develop an approach that, without using the SQuAD training data at all, achieves 56.4 F1 on SQuAD v1.1, and 64.5 F1 when the answer is a named entity mention.
The repository (available here) provides code to run pre-trained models to generate sythetic question answering question data. We also make a very large synthetic training dataset for extractive question answering available.
We also make available a dataset of 4 million SQuAD-like question answering datapoints, automatically generated by the unsupervised system described in the system. Grab them here.
The data is in the SQuAD v1 format, and contains:
| Fold | # Paragraphs | # QA pairs |
|---|---|---|
unsupervised_qa_train.json |
782,556 | 3,915,498 |
unsupervised_qa_dev.json |
1,000 | 4,795 |
unsupervised_qa_test.json |
1,000 | 4,804 |